
Word Tensor Review
Word Tensor
- 만약 word vector를 3D tensor로 만들면 어떨까?
- tensor가 문서 z내에서 단어 x와 단어 y의 관련성을 나타낸다면 doc2vec과 비슷할 것이다. 그래서 word vector뿐만 아니라 document vector또한 얻을 수 있다.
본격적으로 하기 전에 알아둘 개념
- Point-wise MatuaI Information: 두 점 x, y사이의 상관도를 수치화 하는 기법. 이다. 두 변수 사이의 연관도가 높으면 P(x, y)는 P(x)P(y)에 비해 높다. 그리고 그 결과로 는 0보다 커진다. 만약 연관도가 낮다면, 두 변수가 동시에 일어날 확률을 독립이므로 P(x,y)P(x)P(y)이다. 따라서 i(x,y)0이다. 만약 상호 보완적인 관계이면 P(x, y)는 P(x)P(y)에 비해 작은 값을 갖게 될 것이다. 참고 자료
-
PMI Matrix: 각각의 row는 word x를 나타내고 각각의 column은 word y를 나타내는 matrix이다. 각각의 값은 PMI이다. matrix size는 (n_vocabulary, n_vocabulary)이다. 그래서 sparse해질 수 있기 때문에 sparse array data structure를 쓰는 게 좋다.
- tensor factorization은 다음과 같다.
- 2D와 비슷하지만 tensor는 x, y, z 세 개의 변수에 의해 indexing된다. 그리고 2D에서와 마찬가지로 x, y, z가 얼마나 자주 발생했는지 계산하고 p(x), p(y)와 p(z)로 나눠줄 것이다. 이렇게 나눠주면 각각의 단어에 대한 확률을 계산해준다.
- 예시에서는 word x가 비슷한 단어인 word y와 document z내에서 얼마나 자주 같이 발생했는지를 계산할 것이다. z는 각각의 단어 들에 대한 index이다. 그래서 z는 모든 정보를 encode한다.

-
3D tensor를 3개의 2D mode로 쪼갤 수 있다. 하나는 word index x를 위한 거고 다른 하나는 word index y를, 마지막으로 document index z를 위한 것이다. 위의 그림에서 앞면이 word x를 위한 matrix이고 윗면이 word y를 위한 matrix이고 옆면이 document를 위한 matrix인 것 같다.
-
3차원 내에서의 각각의 값들은 x,y,z에 대한 *PMI(x,y,z)이다. document k matrix, word j matrix, word i matrix는 모두 크기가 (100k, 256)이다. 첫번째와 두 번째 mode는 word vector들을 담고 있다. 예시에서는 옷 후기에 대한 word vector들이라고 보면 된다.세번째 mode는 document vector들을 담고 있다. 그래서 하나의 style에 대한 word vector들에 대한 요약이라고 생각하면 된다.
*tensor에 대한 이해를 돕기 위한 이미지

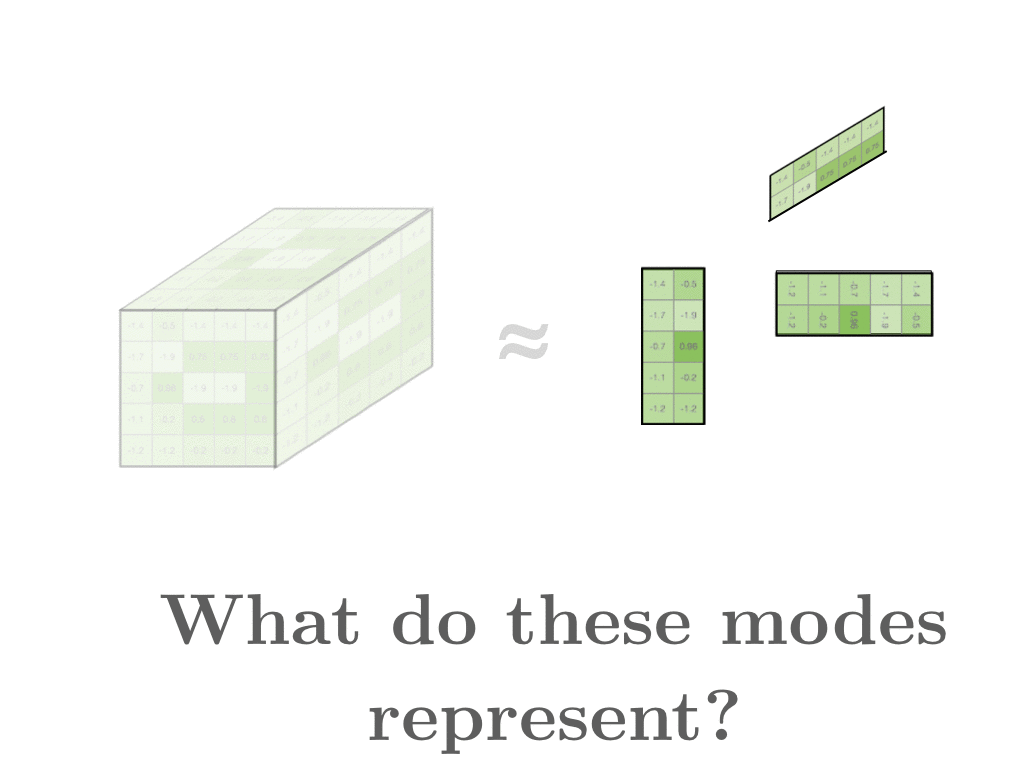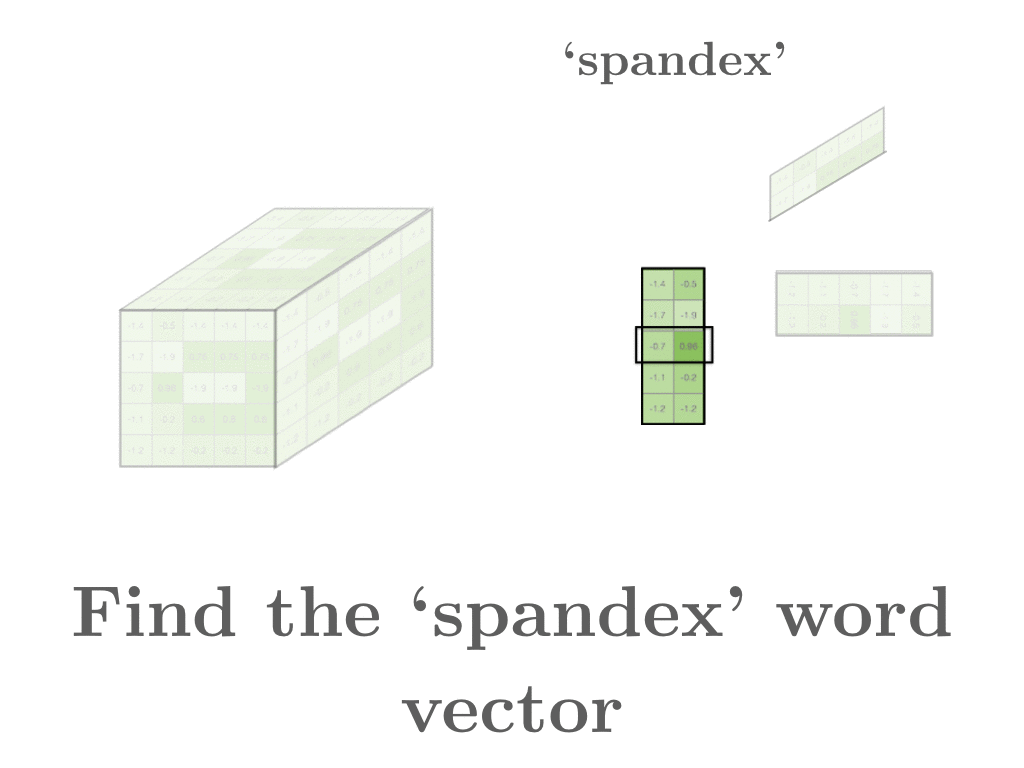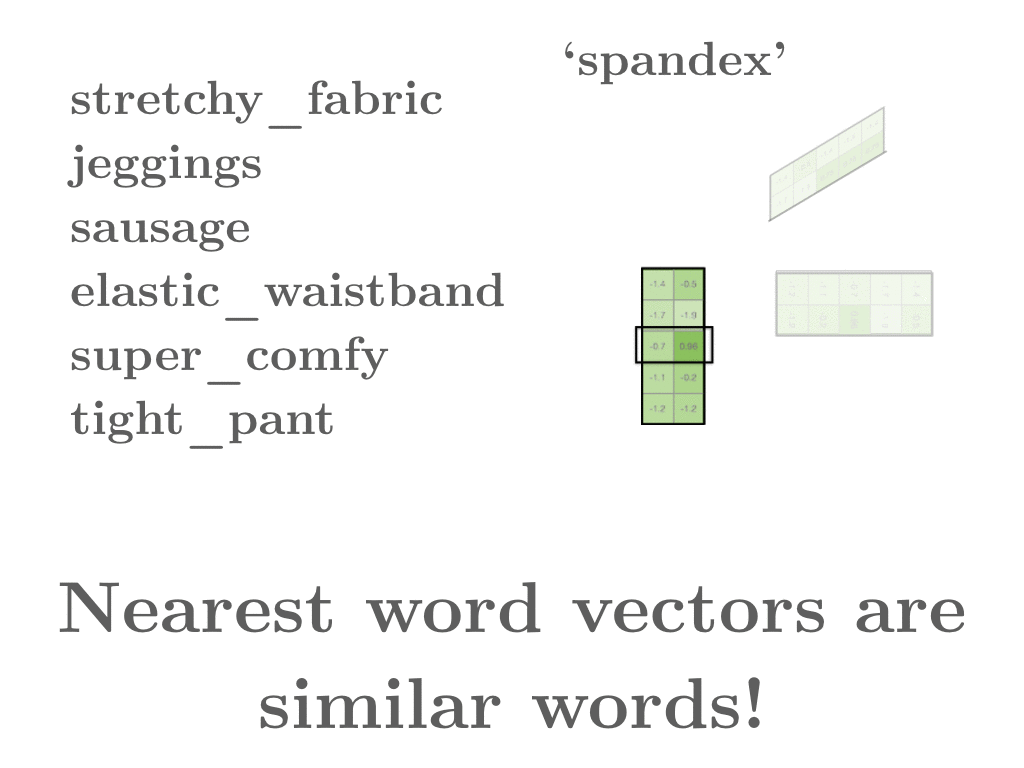
(위의 예시는 옷과 관련해서 예시를 들고 있다.)
- 우리가 ‘spandex’를 찾고 있다고 하자. 두 개의 word matrix중에 하나를 골라서, ‘spandex’에 해당하는 row vector를 골라내고 어떤 row vector들과 비슷한지 비교한다. original word2vec처럼 가까울 수록 비슷한 단어이다. 왜냐하면 가까울 수록 유사한 context에서 등장한다는 것이기 때문이다.
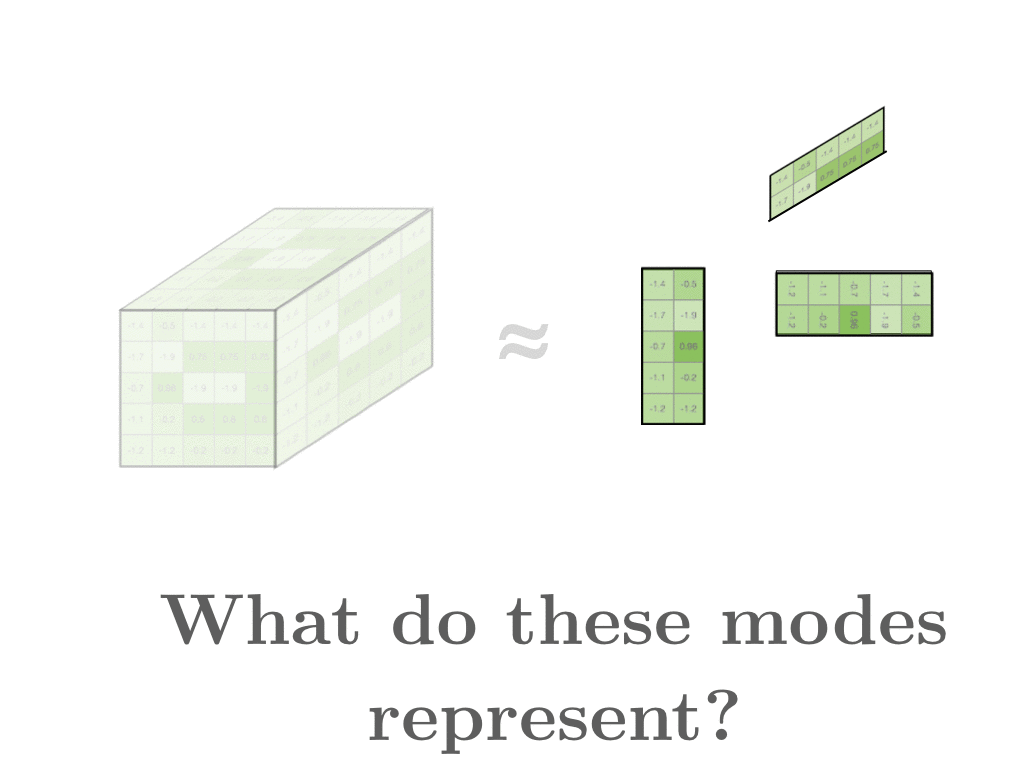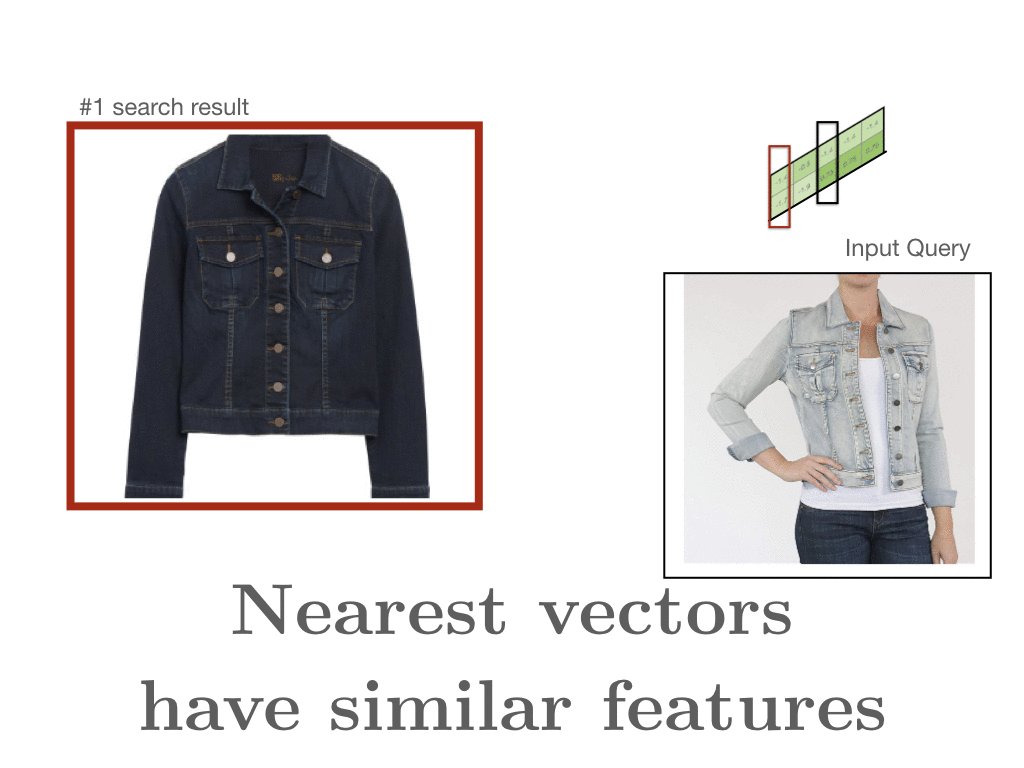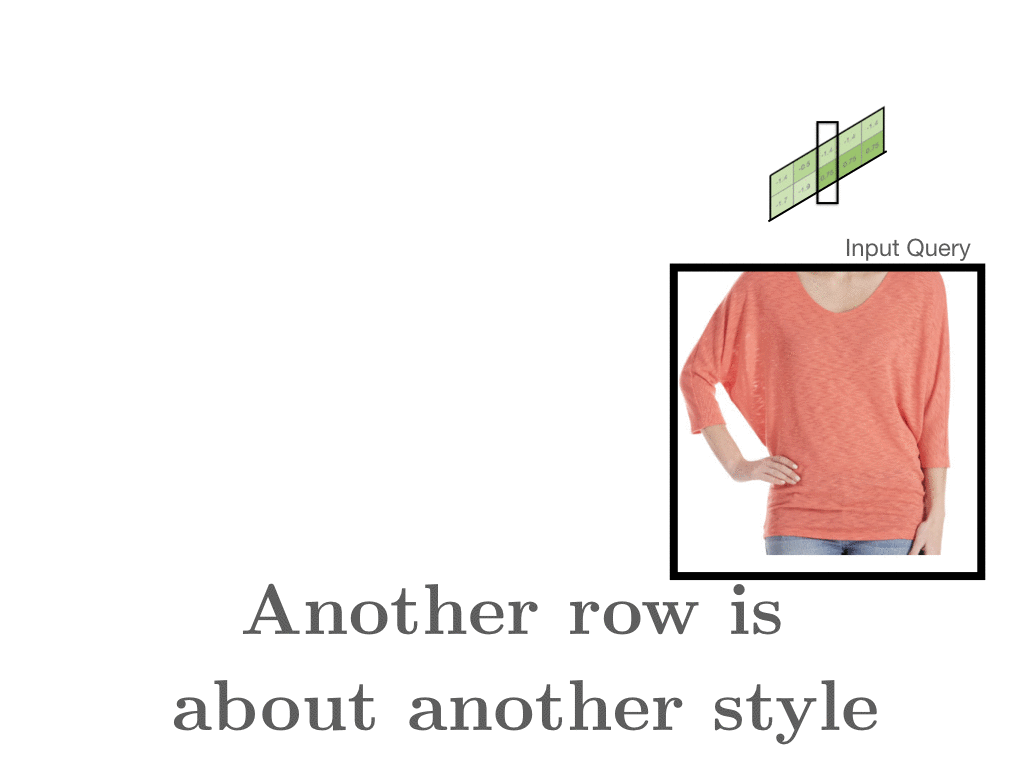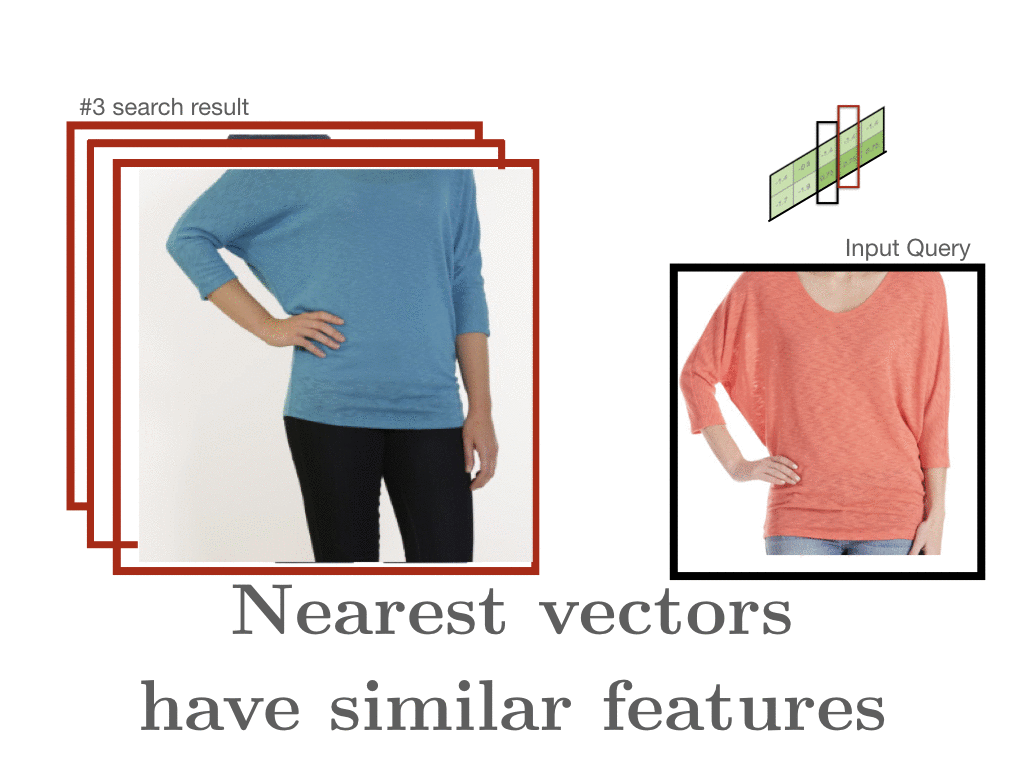
- document matrix는 word x와 word y에 대한 요약이다. 옷 예시로 보면, 하나의 style에 대한 각각의 평가를 합친 게 z이다. 하나의 row는 하나의 style을 나타낸다. 가까운 vector일수록 비슷한 feature를 가진다. 만약 denim jacket과 어떤 게 유사한 지 살펴본다면 denim과 관련된 item이 나올 것이다.

- word와 word, document와 document를 비교할 수 있을 뿐만 아니라, word와 document 또한 비교할 수 있다.
- 그래서 위의 예시에서는 스타일과 description의 유사도 또한 알 수 있다.
Tensor Decomposition
- word tensor를 계산하는데는 딱 3가지 과정만 거치면 된다.
- word-word-document skip-gram을 계산하고 PMI 형식으로 정규화 한 뒤, 작은 matrix들로 factorizing한다.
- 실제로 factorization을 하기 위해서는 SVD를 더 높은 rank의 tensor로 일반화 해야하는 등 이런저런 어려움이 있어서 제대로 구현하는 게 쉽지 만은 않다.
- 그래서 필자는 scikit-tensor에 있는 HOSVD를 추천한다고 한다.
Conclusion
- counting과 tensor 분해는 좋은 기술이다. 하지만 business context에서는 별로 두드러지지 않고 있다.
- 위 예시에서는 document 내에서의 word skip-gram으로 구성된 것을 factorization했다. 그리고 word와 word간의 비교뿐만 아니라 word와 document간의 비교도 가능했다.
- 이러한 분석은 효과적이고 간단하고 강력하다.
- deep-learning에 달려들기 전에 tensor factorization을 한번 써보기 바란다!
Reference
- http://multithreaded.stitchfix.com/blog/2017/10/25/word-tensors/

Leave a comment